fetch
|
|

|
|
g/i/m/y/u
g => 全局查找 从上一次匹配的位置继续寻找直到找到匹配的位置开始,不一定是第一个就匹配上
i => 大小写不敏感
m => 检测字符串中的换行符
y => es6 全局查找 但是 必须是匹配成后紧跟着的第一个字符就要匹配成功才算
u => 用来处理Unicode字符的 大于两个字符(0xffff) .不匹配/量词(大于0xffff)/u{61}(这种Unicode字符)
gulp中使用的是node的stream(流),是以stream为媒介
先读取需要的stream,通过stream的pipe()方法导入到想要的地方,比如插件等,经过插件处理过的流可以继续导入到其他地方,包括写入到文件中
搭建环境 // ok
写页面 // ok
js //
es6 默认就是 严格模式 ‘use strict’
{} 内的变量只有在{}内部才有效,且不能重复声明
const 声明值类型 只读,引用类型可变,且必须赋值
解构赋值:左边一种结构,右边一种结构,一一对应赋值
注:有时候网页采集器中的url获取不到真实数据,就不能抓到数据。
搜索字符=>属性名=>手气不错
就可以抓到数据,有时候要多试几次。
生成区间数=>选择区间(也就是页数)
合并多列=>填写输出列的名称=>Format 填写utl(0)。
从爬虫转换=>一般不用 填爬虫选择
写入数据表=>给数据定义名字
数据库操作
导出=>串行模式/并行模式。
Node.parentNode,Node.childNodes,Node.firstChild,Node.lastNode.
Node.previousSibling,Node.nextSibling.
添加 Node.appendChild()
删除 Node.removeChild()
复制 Node.clone(boolean) =>true 深度克隆 false 只克隆标签
创建 document.createElement()
选择 =>document.getElementById(),getElementsByClassName(),getElementsByTagName(),querySelector
1.性能:getElement(s)By…的性能要比querySelector快很多。
2.querySelector选择出来的是静态的,getElement选出来的是动态的=>比如动态生成的元素可以用querySelector给每一个该对象生成方法。(新建文件夹)
elem.className
elem.classList=>add(class),remove(class),contains(class),item(index),toggle(class,boolean)。
dom批量操作要用createDocumentFragment()
|
|
也可以1234567var d= document.createElement('div'); var html=""; for (var i = counts; i > 0; i--) { html += '<p>i+' hehe'</p>'; } d.innerHTMl = html; document.body.appendChild(d);
总结:innerHTML与createDocumentFragment 都比createElement和append占优势,少量数据时innerHTml最优,多数据或者改数据createDocumentFragment最优
但是innerHTML还有两个缺点:
1.如果你在原来的子元素上绑定了事件的话,重写后事件绑定仍然还在
2.js代码和html代码耦合程度高,不利于维护
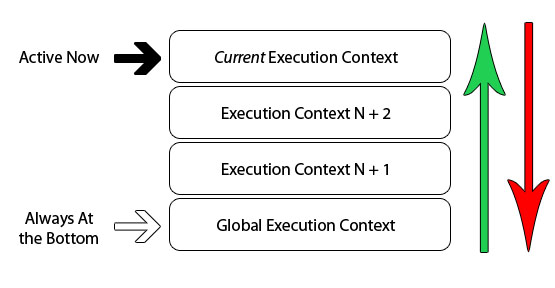
当前代码的运行环境或者作用域
js中代码的运行环境分为以下三种:
全局级别的代码-这个是默认的代码运行环境,一旦代码被载入,引擎最先进入的就是这个环境。
函数级别的代码-当执行一个函数时,运行函数体中的代码
Eval的代码-在Eval函数内运行的代码。
在浏览器中,js引擎的工作方式是单线程的。也就是说,某一时刻只有唯一的一个事件是被激活处理的,其他的事件被放入队列中,等待被处理。
eg:12345678(function foo(i) { if (i === 3) { return; } else { foo(++i); } }(0));
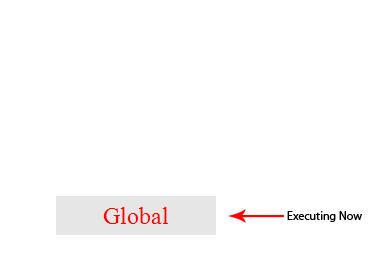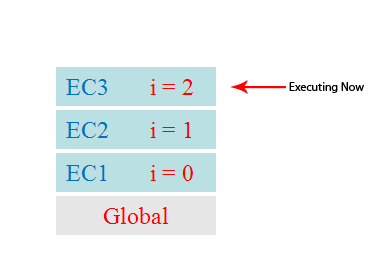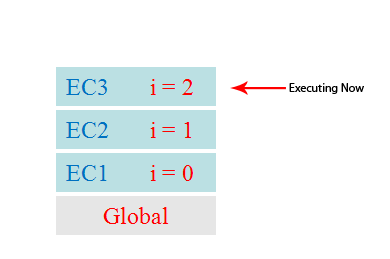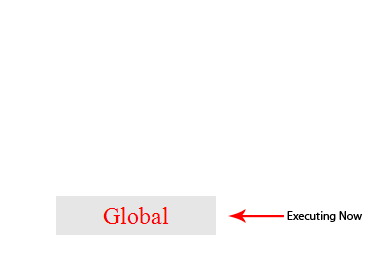
由此可见 ,对于执行上下文这个抽象的概念,可以归纳为以下几点:
单线程
同步执行
唯一的一个全局上下文
函数的执行上下文的个数没有限制
每次某个函数被调用,就会有个新的执行上下文为其创建,即使是调用的自身函数,也是如此。
我们现在已经知道,每当调用一个函数时,一个新的执行上下文就会被创建出来。然而,在javascript引擎内部,这个上下文的创建过程具体分为两个阶段:
建立阶段(发生在当调用一个函数时,但是在执行函数体内的具体代码以前)
建立变量,函数,arguments对象,参数
建立作用域链
确定this的值
代码执行阶段:
变量赋值,函数引用,执行其它代码
|
|
建立阶段1234567891011121314fooExecutionContext = { variableObject: { arguments: { 0: 22, length: 1 }, i: 22, c: pointer to function c() a: undefined, b: undefined }, scopeChain: { ... }, this: { ... } }
执行阶段1234567891011121314fooExecutionContext = { variableObject: { arguments: { 0: 22, length: 1 }, i: 22, c: pointer to function c() a: 'hello', b: pointer to function privateB() }, scopeChain: { ... }, this: { ... } }
我们看到,只有在代码执行阶段,变量属性才会被赋予具体的值。
在函数中声明的变量以及函数,其作用域提升到函数顶部
eg:1234567891011121314(function() { console.log(typeof foo); // function pointer console.log(typeof bar); // undefined var foo = 'hello', bar = function() { return 'world'; }; function foo() { return 'hello'; } }());
mouseover 支持冒泡事件,鼠标移入到子元素也触发mouseover事件。
mouseenter 不支持冒泡事件,鼠标移入到子元素不触发mouseenter事件。